Summarizing America: The Impact of Metadata on Historical Discovery
To complete her undergraduate senior thesis in the comparative history of ideas at the University of Washington, Aashna Sheth worked with Chronicling America data. She is currently pursuing a master’s in computer science at the University of Washington.
Over the past 20 years, the National Endowment of the Humanities (NEH) and the Library of Congress have assembled the largest freely accessible digital archive of historical American newspapers, known as Chronicling America. Funded by grants for up to $325,000 over two years, state and territory-level partners, including catalogers, librarians, computer scientists, and historians, collaborate to grow this collection of 20.5 million newspaper pages spanning almost 4,000 newspaper titles. As detailed in the 2014 impact study, Chronicling America has been used by historians, educators, genealogists, biographers, and other researchers to publish manifold works. Over the last ten years especially, Chronicling America has enabled innovation at the intersection of computing and history, a space encompassed by the field of digital humanities. For example, Viral Texts and Oceanic Exchanges map the national and global exchange of information in the nineteenth and twentieth centuries; Newspaper Navigator makes it possible to search through the 1.56 million photos within the newspaper pages; and America’s Public Bible tracks the citations of the Bible throughout American history.
Central to computational work done with digitized materials is how physical pages are displayed digitally. In Chronicling America, microfilm is the source for most digital images, and the text from these pictures is converted into plain text via optical character recognition (OCR). This text data is then passed through computational algorithms used to search, filter, display, and summarize historical information. Alongside the digitized newspaper files are corresponding metadata files (in the form of text and XML files for OCR data and JPG and PDF files for paper scans). Metadata files contain structured data about the collection of newspaper files, including the newspaper title, place of publication, language, circulation frequency and they are also used in search and filter algorithms. Constructed by state and territory-level partners, metadata files, also known as catalog records, often include information from pre-existing metadata (like old library catalog cards).
The Chronicling America database has two types of metadata for each newspaper publication (at the title level, rather than for each issue or page): a structured data format called a MARC record, and an unstructured, brief newspaper history essay, also called a title essay, that explains the historical significance of each newspaper in about 500 words. Because metadata is so commonly used to filter sources, it has an impact on the research process and accessibility of sources; incorrect or missing metadata can result in a historical source being “lost” (i.e., never shown to users). In the context of historical research specifically, the accuracy and thoroughness of metadata relate directly to which sources and voices are studied and taught. Thus, investigating the metadata accompanying sources becomes equally important as studying the sources themselves. In what follows, I explore how metadata is useful not only for answering questions about the contents of the sources but also about what and whom the sources represent.
For my senior thesis, I extended work done by previous NEH interns Joshua Oritz Baco, Jeannette Schollaert, and Daniel Evans who researched Chronicling America metadata. In August 2020, Ortiz Baco used the title essay metadata to create and update Library of Congress Name Authority Files (LCNAF) for editors and publishers described in the title essays. The following summer, Schollaert continued this work with LCNAF records. In February 2023, Evans released a dataset of Chronicling America metadata including each newspaper’s MARC record and title essay, primed for further computational analysis. I used Ortiz Baco’s and Schollaert’s background about title essays and Evans’s dataset to explore the differences between structured and unstructured metadata in Chronicling America and to further investigate the contents of title essays.
I started my computational analysis by extracting basic counts and frequencies of words in the MARC records and title essays accompanying each publication, hoping to compare the contents of the two. After finding that the most common MARC subject headings were African Americans, United States, District of Columbia, Washington, Vermont, Delaware, Wilmington, Germans; and after looking into more examples manually, I realized that MARC records in Chronicling America primarily contain keywords about the locations and ethnic populations the newspapers were created for or by. For this reason, comparing the contents of MARC records and title essays directly seemed ineffective because they contained such different information. As I turned my analysis to the title essays, I noticed that not all newspaper titles have attached essays yet. Here, the structured information contained in the MARC records helped me further investigate which sources were lacking metadata. After grouping publications without title essay information together, the top tags included Japanese Americans (27 papers), United States, District of Columbia, Washington (23 papers), and Washington (D.C.), Newspapers (23 papers). These tags show which categories partners are still working on adding metadata for.
To analyze the contents of the 1,865 remaining informative title essays, I used a machine learning technique called topic modeling, which is commonly used to identify recurring themes or topics across different texts. Topic modeling algorithms look at the frequency of words across a collection of documents and cluster them into topic groups; documents that have similar keywords will all be placed together. A popular implementation of topic modeling is included in the open-source software package MALLET. Before running MALLET on the title essay data, I removed duplicate essays and the filler words in each essay (articles and commonly used verbs and nouns) to help the algorithm pick up on significant terms. After trying a varying number of topic groups and evaluating them for qualitative and quantitative coherency, I found that grouping the title essays into 30 groups led to the emergence of interesting patterns.
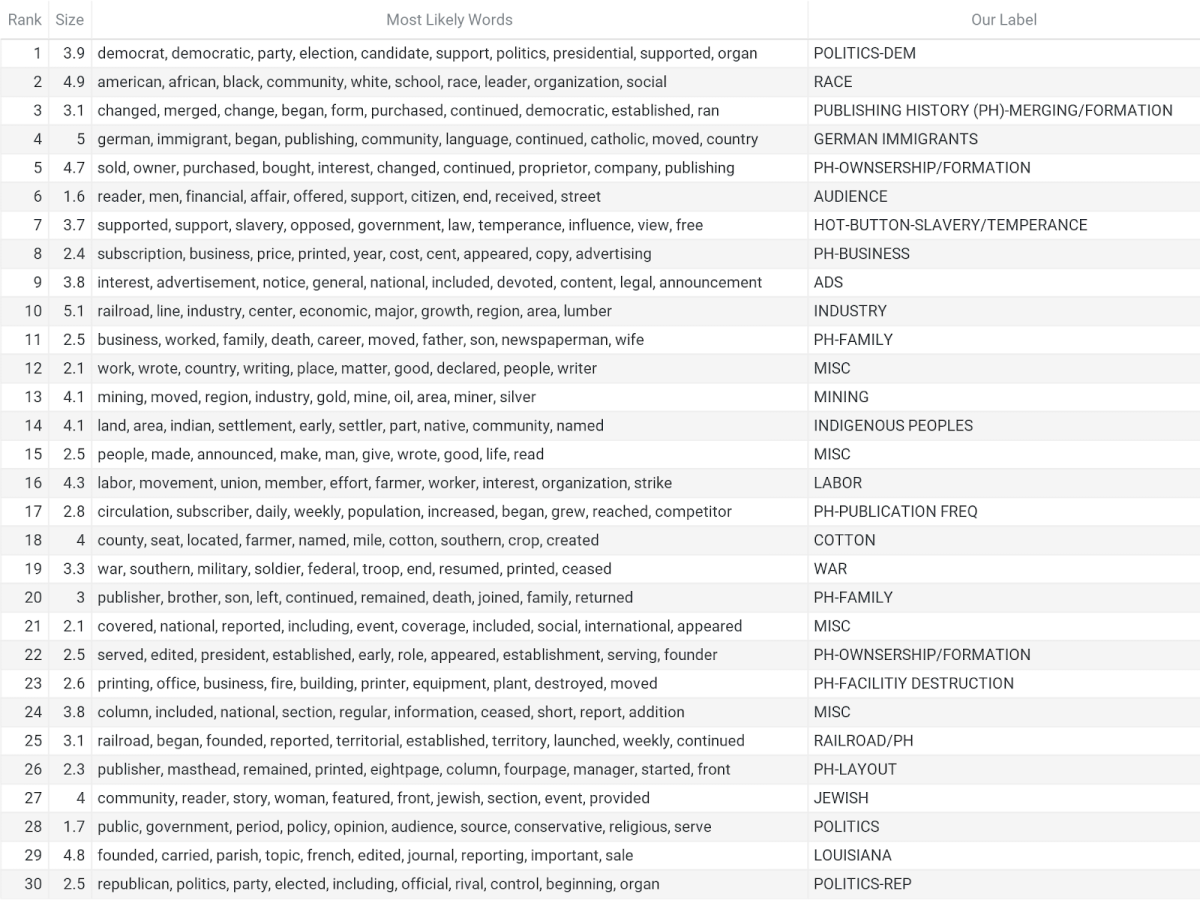
The list of topics generated by the topic modeling algorithm, alongside cluster labels and other cluster metadata

The list of topics generated by the topic modeling algorithm, alongside cluster labels and other cluster metadata
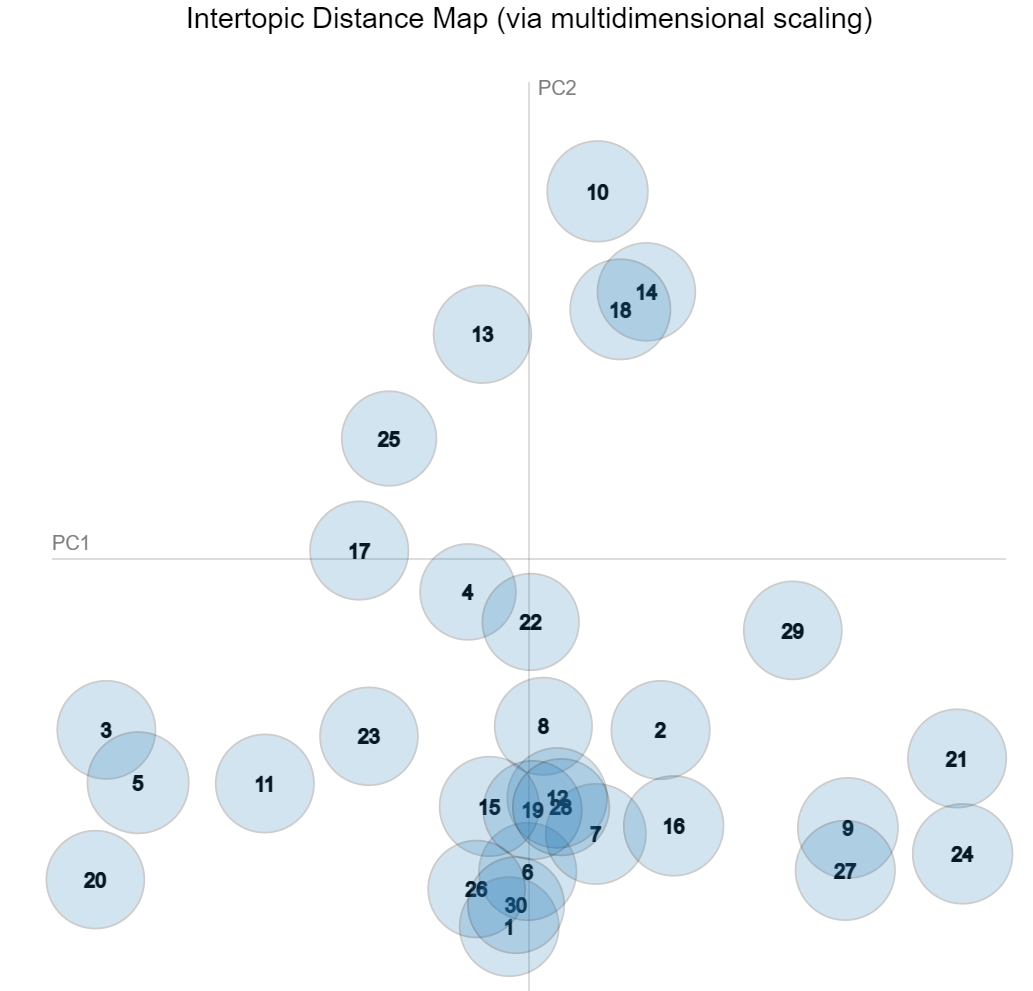
Spatial visualization of the topic clusters

Spatial visualization of the topic clusters
The first image shows the top ten words in each of the 30 topics and includes a label I created for each category. The following image shows a visualization of the clusters, where each cluster is represented by a circle. The size of the circle represents the size of the cluster (MALLET usually results in equally sized clusters) and the distance between the circle represents how similar clusters are. The closer together the clusters, the more similar words they contain.
Given the labels for each category, we see that title essays discuss many of the topics specified by the NDNP guide for title essays. Excitingly, we can see specific information about these guidelines. The guidelines indicate that title essay creators should cover “changes in name, format, and ownership” as well as the “geographic area covered” by newspapers. Several topic clusters contain words like “brother,” “son,” “wife,” “death,” “family,” “career,” and “publisher” (#11, #20) revealing that changes in company ownership follow familial ties, showing publishing companies have been historically family owned. Other topic clusters containing industrial terminology like “railroad”, “lumber” (#10), “oil”, “gold” and “silver” “mining” (#13), and “cotton” in the “south” (#18) disclose the topics that newspapers covered, the areas they served, and even how they may have started (for example, railroads helped establish the city of Albuquerque and the Albuquerque Weekly Citizen publication). The NDNP guide also recommends the title essay contributor write about the “political, religious, and ethnic affiliations” of newspapers. We can see that topic #2 includes newspapers with affiliations to Black communities (“African,” “American,” “Black,” “white,” “school,” “race,” “leader”), topic #4 includes newspapers with affiliations to German communities (“German,” “immigrant,” “moved,” “Catholic,” “language,” “country”), and topic #7 includes papers with political affiliations regarding hot-button issues (“slavery,” “temperance,” “support,” “opposed”).
We can also examine which title essays fell under each topic cluster. Close reading of the title essays within topics can be a great starting point for further historical inquiry. For example, I was interested in the appearance of “schools” in topic #2. After reading several title essays grouped under this topic, I saw that a large proportion of title essays for African American presses include sections about Black schools (Athens Republique), segregation in schools (Chicago Reflector), and Baptist schools (American Baptist).

Screenshot of the title essay for The Athens Republique, mentions all-Black schools
Credit: Chronicling America

Screenshot of the title essay for The Athens Republique, mentions all-Black schools
Credit: Chronicling America

Screenshot of the title essay for The Chicago Reflector, mentions segregation in schools in the late 1800s.
Credit: Chronicling America

Screenshot of the title essay for The Chicago Reflector, mentions segregation in schools in the late 1800s.
Credit: Chronicling America

Screenshot of the title essay for The American Baptist, mentions Baptist schools.
Credit: Chronicling America

Screenshot of the title essay for The American Baptist, mentions Baptist schools.
Credit: Chronicling America
The newspapers that fall under each topic category can be found here and the code to generate these outputs can be found here. It is important to recognize that MALLET outputs are by no means perfectly accurate or all-encompassing; some topics may be missing, and others may be grouping ideas that are not related. In the context of historical research, topic modeling can be considered a wayfinding mechanism through a collection of documents; not necessarily providing conclusions, but offering a starting point of groups of title essays to look at and motivating hypotheses that can be confirmed by close reading.
Through this work, we can see how metadata interacts with historical sources to illuminate trends and shape our inquiries. Ensuring complete metadata for all sources is a form of digital representation and actualizes the benefits of a digital repository as a platform for historical discovery. The catalogers, contributors, and coordinators of Chronicling America do the important work of updating and writing new metadata to ensure that historical information, even the seemingly factual contents of newspapers, is backgrounded by entities that wrote it; and the rich contents of Chronicling America title essays is a testament to benefits of consciously curated metadata.
I would like to thank Molly Hardy, Benjamin Lee, and Anna Preus, for their guidance, feedback, and mentorship throughout this project.